
 01
01AI & Machine Learning
Your Phone Lines Don't Need to Sleep Anymore
February 21, 2026
01 02
02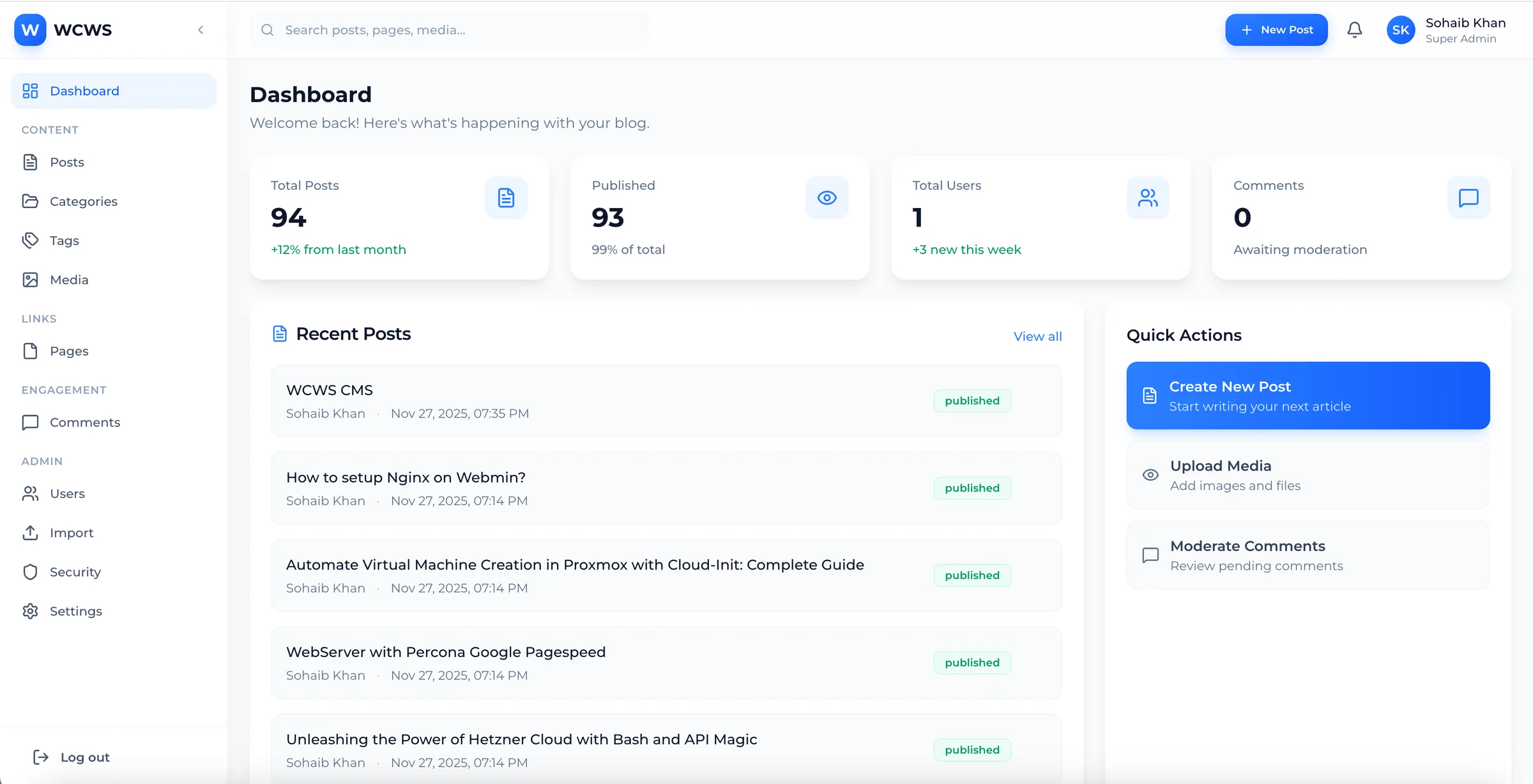 03
03 04
04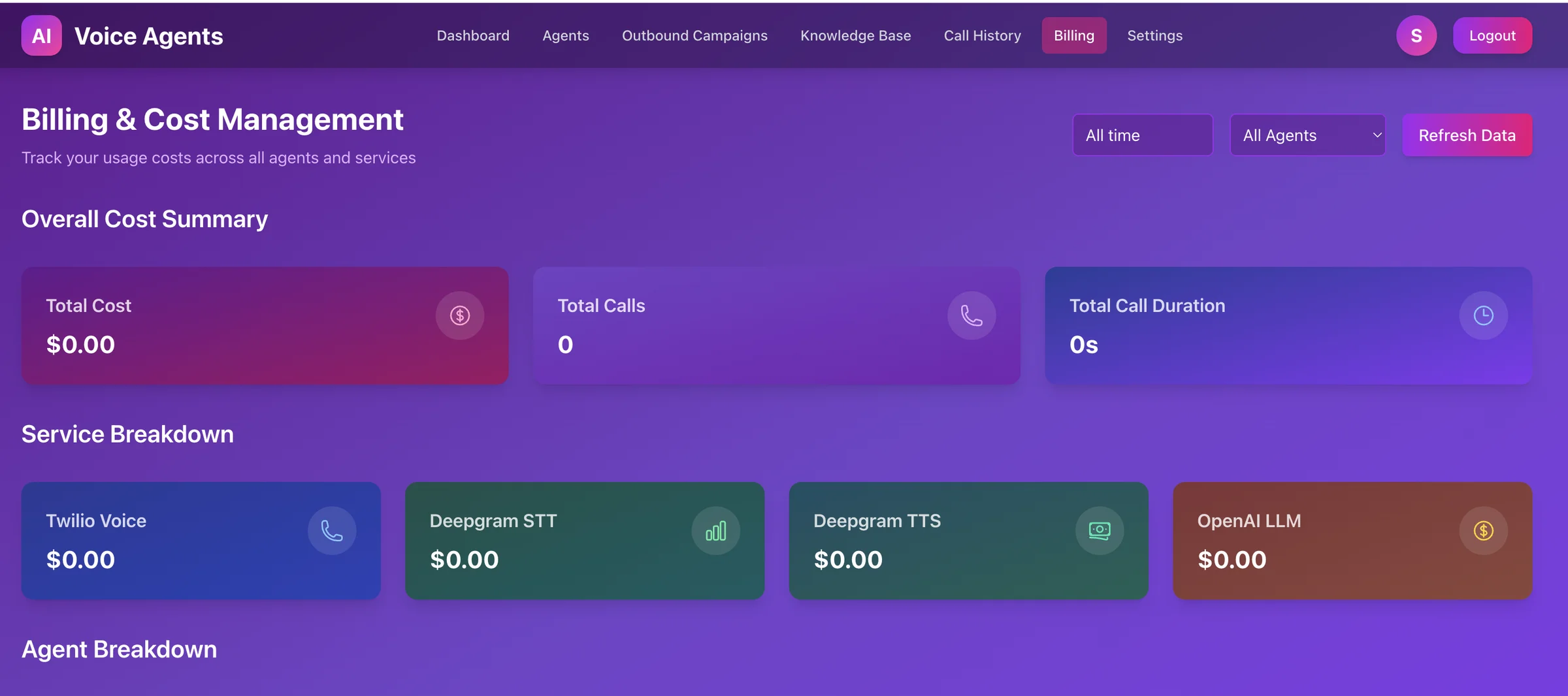

In today’s fast-paced world, seamless communication is more crucial than ever. Whether it’s connecting with customers or managing internal calls, the ability to...

In a world where technology streamlines processes, the human touch remains essential, especially in interviews. You might wonder how an AI Interview Assistant c...

Introduction Securing your server is a critical aspect of maintaining a robust and reliable online presence. Bitninja, a comprehensive security solution, provid...

Keeping your essential services running smoothly is crucial for any server. Ensuring that services like Nginx and MariaDB are always up and running can be a dau...
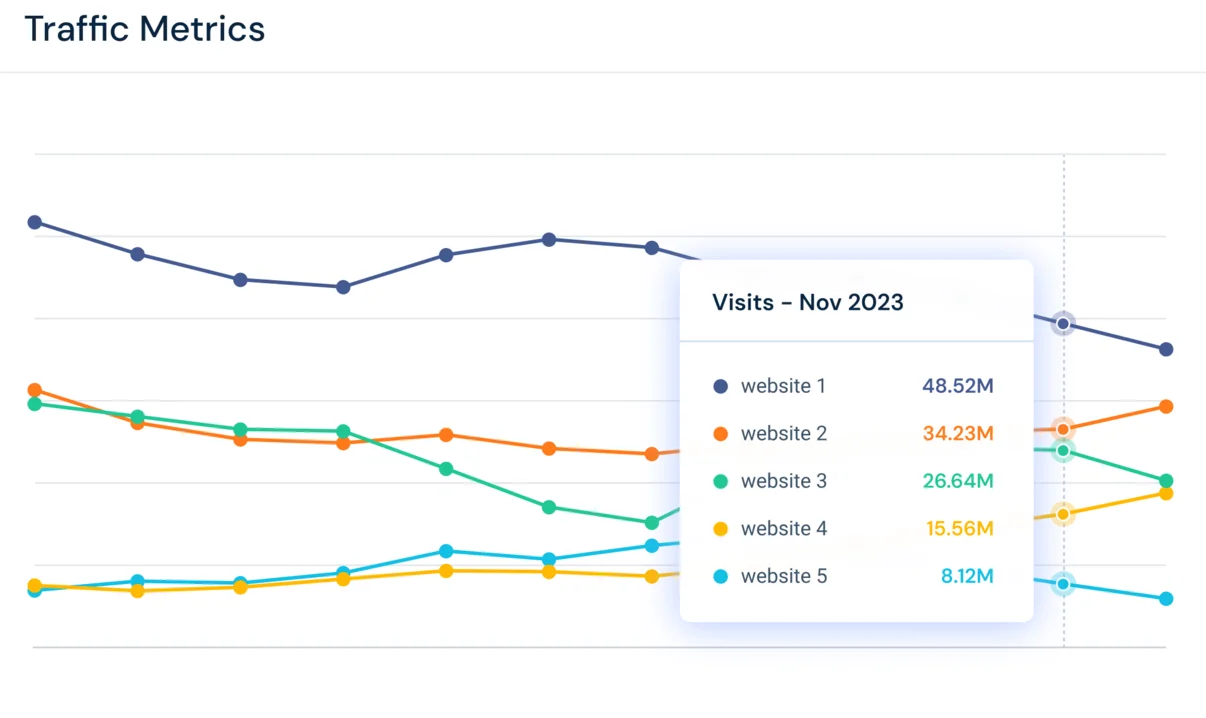
In the world of website management, keeping track of traffic is essential. Monitoring access logs can help you understand the volume of traffic and identify pot...
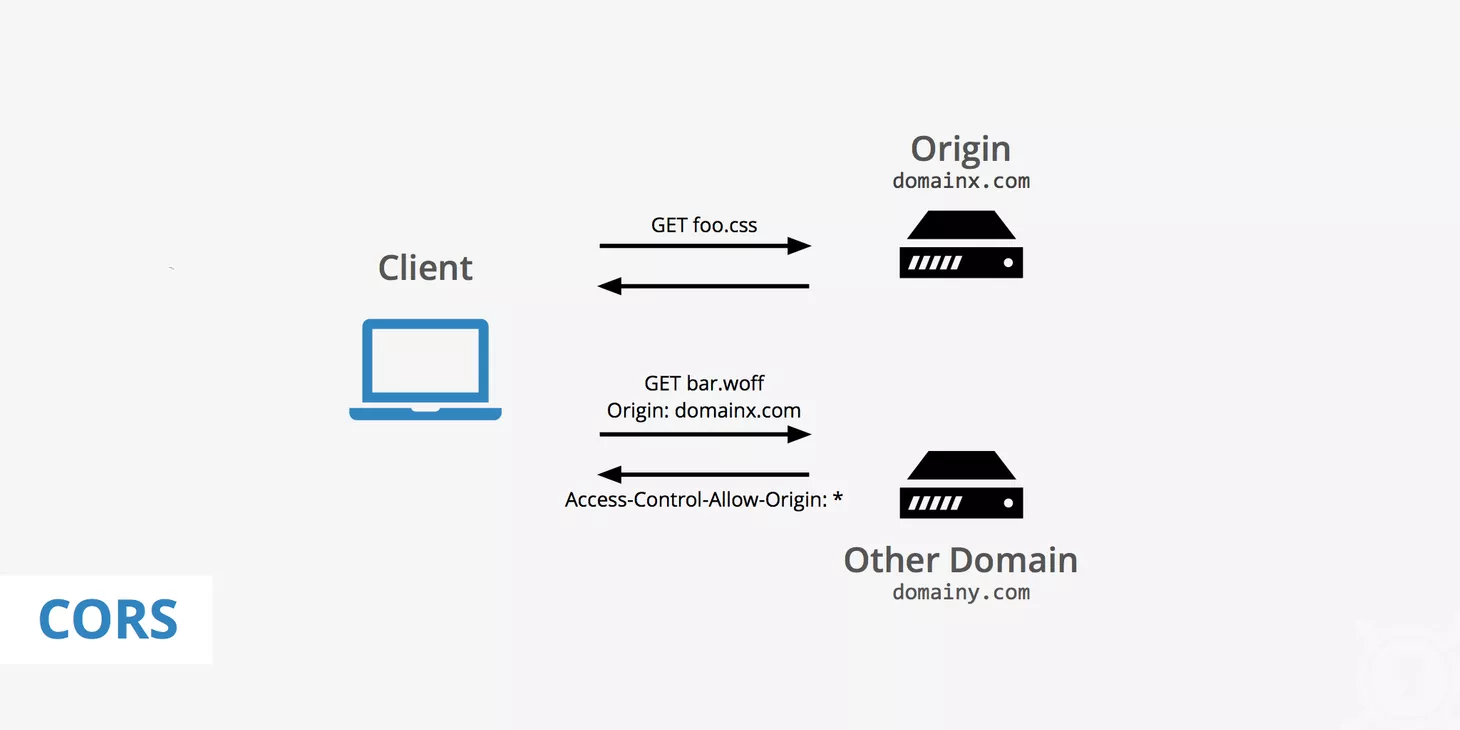
We've all been there. You're managing your website, everything's running smoothly, and then—bam! You decide to change your domain from https://www.mydomain.com...
Page 1 of 10 • 96 articles