I Was Diagnosed With Cancer. So I Built an Open-Source Platform to Help Researchers Test More Ideas.
When I was diagnosed with oral squamous cell carcinoma, or OSCC, I started looking for answers.
What I found was a field doing extraordinary work, but much of its knowledge was spread across expensive paywalls, disconnected databases, specialist software, and command-line tools that most people cannot easily use.
Cancer research does not have an ideas problem. It has an access, integration, and validation problem.
So I built NaturaScreen.
https://naturascreen.sohaib.com
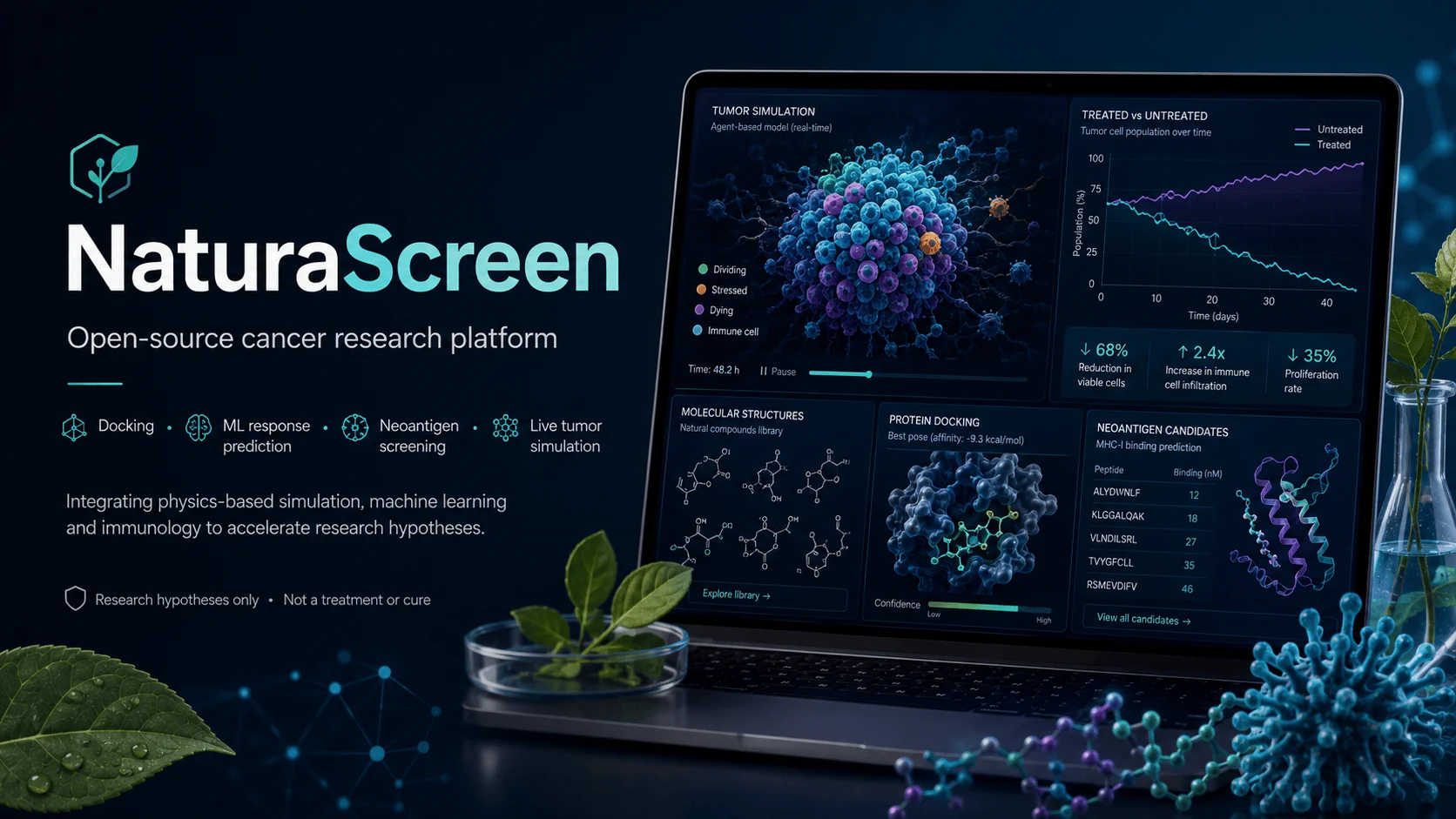
NaturaScreen is an open-source research platform for screening natural compounds against cancer-related proteins and tumor-specific neoantigens. It combines molecular docking, machine-learning response estimates, and a live agent-based tumor simulation in one system.
Its purpose is simple:
Help researchers, students, and independent investigators test more research hypotheses, faster, using open tools and honest outputs.
NaturaScreen does not produce cures. It does not recommend treatments, doses, or medical decisions. Every result is a research hypothesis that requires laboratory investigation.
That boundary is not buried in fine print. It is built into the software.
What NaturaScreen does
A researcher can use NaturaScreen to:
Search an open library of natural compounds
Dock compounds against curated cancer-protein binding sites
evaluate peptide–MHC presentation for tumor neoantigens
Estimate drug-response signals using an XGBoost model trained on GDSC1 data
Explore an illustrative agent-based tumor simulation
Rank candidates for further laboratory investigation
Feed experimental results back into the system
The goal is not to declare that a compound works.
The goal is to identify which questions may be worth testing next.
Watch a tumor simulation unfold in real time
One of NaturaScreen’s most visible features is its live simulation explorer.
The interface streams an agent-based tumor model in real time. Individual cells are shown as dividing, stressed, or dying, while a population chart compares treated and untreated conditions. Researchers can pause the simulation, replay it, and adjust an effectiveness parameter.
But this distinction matters:
The simulation is an illustration of the platform’s effectiveness score. It is not a prediction of how a real tumor or patient will respond.
There is no validated equation that converts a molecular binding score into a tumor-growth rate. NaturaScreen therefore uses a named and documented illustrative component called HeuristicEffectTransfer.
The simulation notice appears on the opening stream envelope, on every frame, and inside the three-dimensional viewer. The viewer will not render cells unless that notice is displayed.
That is intentional.
Scientific software should communicate uncertainty at the point where a result is seen, not several pages later.
Two boundaries the software cannot bypass
NaturaScreen enforces two non-negotiable boundaries through its type system.
1. The cure boundary
Every result, API response, report, and export contains a mandatory disclaimer stating that the output is a research hypothesis, not a cure, treatment, dose, medical recommendation, or result validated for human use.
The disclaimer is a required Pydantic field. It cannot be disabled.
The frontend cannot render a report without it.
2. The simulation boundary
Every simulation carries a notice explaining that it is a qualitative illustration, not a tumor-response prediction.
The notice travels with the stream and every generated frame. It cannot be separated from the visualization.
These constraints are not cosmetic safety labels. They are part of the data model.
The scientific pipeline
NaturaScreen brings several established open-source tools and datasets into one reproducible workflow.
StageFunctionTools and dataCompound libraryNatural products, SMILES, and molecular descriptorsCOCONUT and RDKitMolecular dockingEstimated binding affinity against curated protein pocketsAutoDock Vina and MeekoNeoantigen analysisPeptide–MHC presentation percentile rankingMHCflurryResponse modellingPredicted cell-line ln(IC50) with an out-of-distribution flagXGBoost trained on GDSC1Tumor simulationIllustrative agent-based cell-population modelNumPy
The platform runs through FastAPI, PostgreSQL, Redis, Celery, Next.js, React, Three.js, and Docker. A synchronous local path using SQLite is also available for people who do not want to run the full service stack.
What the platform refuses to fake
Scientific software often looks more certain than the underlying evidence warrants. NaturaScreen is designed to expose those limits instead.
When an adapter has not been installed or provisioned, NaturaScreen reports it as unavailable. It does not generate a placeholder score.
When one component of a compound score is missing, the platform excludes that component and renormalizes the remaining weights. It does not silently replace missing evidence with zero.
Every normalized score includes the fixed reference window used to calculate it.
The simulation term defaults to a weight of zero, preventing an illustrative visualization from being counted as independent scientific evidence.
The response model also includes an applicability warning. Because the model is trained largely on synthetic drugs from GDSC, most natural products may be outside its training distribution. Each prediction therefore carries a nearest-neighbour Tanimoto similarity flag.
A number without its limits is not an honest result.
What has actually been tested
NaturaScreen is not a collection of disconnected interfaces. Core parts of the pipeline have been executed against real benchmarks and datasets.
Molecular docking
A live AutoDock Vina run using the 1IEP receptor and imatinib benchmark returned a binding affinity of −13.28 kcal/mol on the Linux AMD64 worker platform, matching the published benchmark value.
Neoantigen analysis
Live MHCflurry tests ranked known CMV and influenza epitopes as strong peptide–MHC binders, with percentile ranks of approximately 0.02 to 0.13.
A poly-alanine negative control ranked at approximately 9.5, consistent with non-binding behaviour.
Drug-response modelling
The response model was trained on real GDSC1 data:
307 drugs
Approximately 120,000 cell-line and drug observations
Measured LN_IC50 response values
A random-split cross-validation produced an R² of approximately 0.76.
That number looks strong, but it is not the most honest test for NaturaScreen’s intended use.
When compounds were held out entirely, the R² fell to approximately 0.05. This leave-compounds-out result better represents the difficulty of predicting responses for previously unseen natural products.
Both metrics are exposed through the platform’s /meta endpoint.
The weaker number is not hidden because it is the more relevant one.
Structure-only generalization to new natural compounds remains a hard, unsolved problem. NaturaScreen should show researchers that difficulty rather than disguise it.
Run NaturaScreen locally
The full stack can be started with Docker:
git clone https://github.com/sohaibwcws/naturascreen
cd naturascreen
cp .env.example .env
make up
make migrate
make ingest-compounds n=300
Then open:
http://localhost:3000
This starts PostgreSQL, Redis, the API, Celery workers, scheduled tasks, and the web application.
To provision the scientific adapters:
make curate-targets
make data-mhcflurry
make data-response
A service-free local route using SQLite and synchronous experiments is documented in the repository for developers who do not want to run Docker.
Production deployment
NaturaScreen includes a production Docker Compose configuration behind Caddy, with automatic HTTPS, PostgreSQL, Redis, Celery, API-key authentication, and Redis-backed rate limiting.
cp deploy/.env.example deploy/.env
docker compose \
-f deploy/docker-compose.prod.yml \
--env-file deploy/.env \
up -d --build
The deployment requires values for the application domains, database password, and NaturaScreen API keys.
Built on open science
NaturaScreen exists because researchers and maintainers made their work available to others.
The project builds on:
COCONUT
GDSC
PubChem
RCSB Protein Data Bank
RDKit
AutoDock Vina
Meeko
MHCflurry
TensorFlow and Keras
XGBoost
scikit-learn
pandas and NumPy
FastAPI
PostgreSQL
Redis
Celery
Next.js
React
Three.js
Docker
Caddy
The underlying science and engineering belong to the people and organizations that created and maintain these projects. NaturaScreen connects their work into an accessible research workflow.
Correct attribution matters. Any missing or incorrect credit should be reported through a repository issue.
Why I am making it open source
No single lab, model, dataset, or software platform will solve cancer.
Progress comes from researchers testing claims, reproducing results, rejecting weak hypotheses, and sharing what survives.
NaturaScreen is my contribution to that process.
I built it because cancer became personal. I released it because the tools for investigating cancer should be easier to inspect, run, question, and improve.
The project now needs researchers, computational biologists, medicinal chemists, machine-learning engineers, students, and laboratories willing to test its hypotheses against real experimental evidence.
Here is how you can help:
Star and share the repository. Open-source projects depend on reach.
Contribute code or scientific review. Better target curation, evaluation methods, models, interfaces, and documentation are all valuable.
Bring laboratory data. Negative results are as important as positive ones. Both can help show which hypotheses survive contact with biology.
Challenge the assumptions. Find weak mappings, inappropriate metrics, dataset leakage, missing controls, or misleading visualizations. Open science improves when people try to break it.
NaturaScreen is free, open, and ready to run:
GitHub: https://github.com/sohaibwcws/naturascreen
Every result is a hypothesis.
Every hypothesis still has to earn its place in the lab.
Medical and scientific disclaimer
NaturaScreen is a research and educational platform. It does not provide medical advice, diagnosis, treatment recommendations, cures, doses, or clinical predictions. Its outputs have not been validated for human use and require independent laboratory and clinical investigation.
The tumor simulation is a qualitative illustration of a computational effectiveness score. It is not a prediction of tumor behaviour or patient response.
Anyone facing cancer should work with qualified medical professionals.
Related Articles
You might also like
View all

Comments (0)
No comments yet. Be the first to comment!